

forWoT project
forWoT project

Challenge
Develop an explainable transformer-based ontology matching application through “tag clouds” to emphasize the interoperability needs for the Web of Things and enable semantic search for ontological terms.
Solution
forWoT is a solution that aims at processing existing IoT-based ontological entities, using deep learning-based natural processing algorithms, to capture their semantics. This accelerates the ontology matching and/or creation processes significantly, since the ontology experts will focus directly on merging the highlighted entities/properties included in two or more domain ontologies and not perform an exhaustive search over all the included terms.
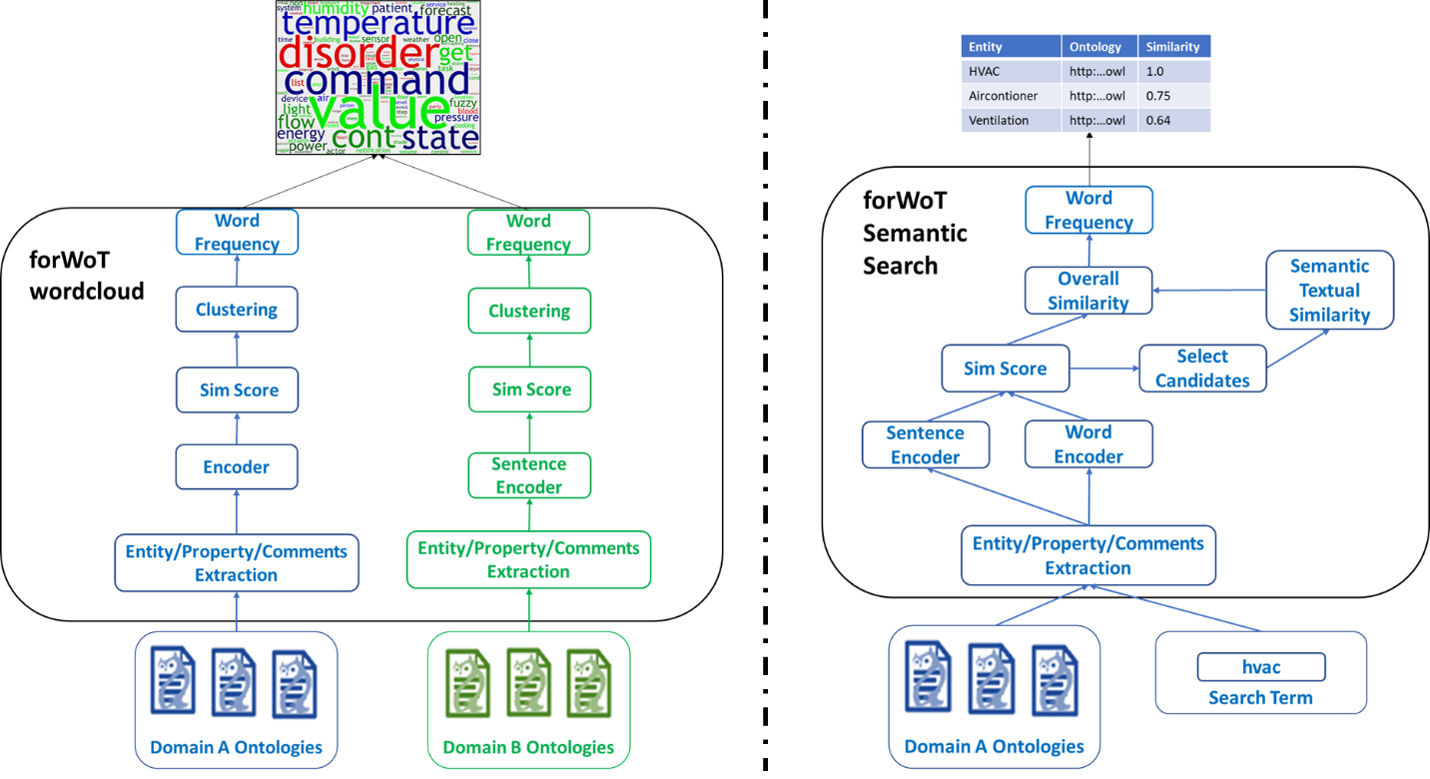
To achieve this, we have developed a RESTful interface with the lov4iot platform (https://lov4iot.appspot.com/) that fetches (one per day) all the existing per ontologies. Afterwards, their entities are extracted using the Ontospy framework and they are preprocessed (i.e., lower-cased, remove special chars and digits, remove stop words, tokenized) using the Re and NLTK python frameworks. The preprocessed entities are represented as word/sentence embeddings (latent space vectors) using the sentence RoBERTa model (https://github.com/UKPLab/sentence-transformers) and stored in a PostgreSQL database. These embeddings are retrieved to define the degree of the similarity between the entities and are exploited during:
1. The word cloud representation functionality, where we use the hierarchical clustering method provided by sklearn library to group together similar terms. Afterwards, we count the most common words in every group and provide the Word Cloud, using the wordcloud library. It should be noted that we use different coloring per domain and for their intersection when the user has added more than one domain.
2. The probabilistic search functionality, where we apply first cosine similarity, and then subsample the eight most common entities for each ontology. The results are, afterwards, fed to a fine-tuned version of RoBERTa, trained on Semantic Textual Similarity (STS) using the transformers library, to produce another similarity metric. The final similar entity retrieval takes into consideration both the two finetuned thresholds on the similarity scores provided by the STS RoBERTa and the sentence embeddings. For the case of deterministic search, we use only regular expressions.
It’s worth mentioning that we utilize torch serve to accelerate and scale the deep learning model’s inference. Finally, we have implemented an ontologist-friendly single page application (SPA) using Vue.js, where the user can access the forWoT solution.
Availability
forWoT beta prototype has been containerized and uploaded in the AI4EU platform
Video:




